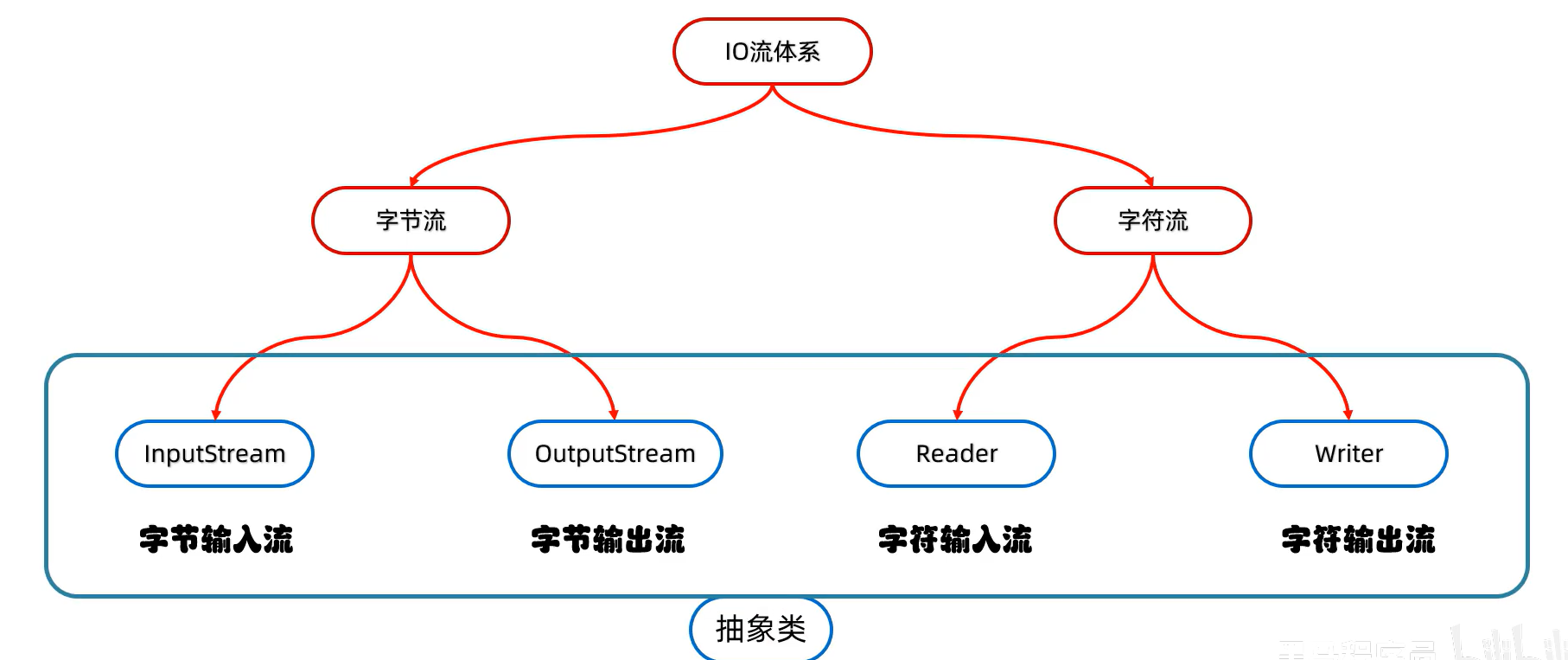
IO
io流
存储和读取数据的解决方案,用于读写文件中的数据(以程序为参照,程序在读取文件或网络上的数据或向文件或网络上写入)
可分为输入流和输出流;或者字节流和字符流(其中字节流可以是所有类型的文件,字符流只能是纯文本文件(利用windows记事本能打开并且能读懂的文件,如.txt,.md))
使用io流的基本原则:什么时候用什么时候创建,什么时候不用什么时候关闭
字节流
FileOutputStream和FileInputStream是字节流的两个实现类:
通过创建它们的对象可以实现对文件的写入和读取操作
FileOutputStream写数据的三种方式

1 | //FileOutputStream写数据程序 |
FileInputStream读数据的两种方式:
注意,第二个方法一次读取一个字节数组的数据,适用于比较大的文件,
可以结合String的有参构造方法控制读数组中的哪几个连续数据

1 | //1.创建对象 |
文件复制
1 | //文件复制程序 |
捕获异常
在字节流中,无论程序中是否存在异常,最后都需要关流,因此有try-catch-finally来满足此需要,finally中包含的程序是try-catch中无论是否捕捉到异常都会执行的,因此可以把关流的语句放在此处,但是此处一处另一个问题,如果在try中创建字节流对象,那么字节流对象的作用域仅限域try所在的大括号而无法作用于finally中,因此需要将创建字节流对象的语句移动至try的上方,并且赋初值Null,否则会报错。
1 | //1.创建对象 |
后续java改进了此做法,使try后面的小括号中可以添加对象参数,但是只有实现了AutoCloseable接口的类,才能在小括号中创建对象,因为创建对象的代码可能太长,因此还可以在创建对象后直接传入。此时资源用完后会自动释放,不再需要手动释放。

字符流
字符集(GBK,UTF-8)
1.在计算机中,任意数据都是以二进制的形式来存储的
2.计算机中最小的存储单元是一个字节
3.ASCII字符集中,一个英文占一个字节
4.简体中文版windows,默认使用GBK字符集
5.GBK字符集完全兼容ASCI字符集
一个英文占一个字节,二进制第一位是0
一个中文占两个字节,二进制高位字节的第一位是1
GBK
计算机的存储规则(汉字)(GBK)
规则1:汉字两个字节存储
规则2:高位字节二进制一定以1开头,转成十进制之后是一个负数
计算机的存储规则(英文)(GBK)
规则:英文一个字节存储,兼容ASCI,二进制前面补0
因此,可以通过观察首位是0还是1来判断该字节表示的是英文还是中文
UTF-8
Unicode字符集的UTF-8编码格式
一个英文占一个字节,二进制第一位是0,转成十进制是正数
一个中文占三个字节,二进制第一位是1,第一个字节转成十进制是负数
产生乱码的原因是编码和解码所采取的编码方式不同,可以通过以下方式避免:
1.不要用字节流读取文本文件
2.编码解码时使用同一个码表,同一种编码方式
java中编码的方法

字符流
字符流是在字节流的基础上加入了字符集
特点:
输入流:一次读一个字节,遇到中文时,一次读多个字节
输出流:底层会把数据按照指定的编码方式进行编码,变成字节再写到文件中
FileReader和FileWriter
FileReader
1.创建字符输入流对象
public FileReader(File file)
创建字符输入流关联本地文件
public FileReader(string pathname)
创建字符输入流关联本地文件
2.读取数据
public int read()
读取数据,读到末尾返回-1
public int read(char[ ] buffer)
读取多个数据,读到末尾返回-1
细节1:按字节进行读取,遇到中文,一次读多个字节,读取后解码,返回一个整数
细节2:读到文件末尾了,read方法返回-1。
3.释放资源
piblic viod close()
1 | //1.创建对象并关联本地文件 |
FileWriter
构造方法:

成员方法:

1.创建字符输出流对象
细节1∶参数是字符串表示的路径或者File对象都是可以的
细节2:如果文件不存在会创建一个新的文件,但是要保证父级路径是存在的
细节3:如果文件已经存在,则会清空文件,如果不想清空可以打开续写开关
2.写数据
细节:如果write方法的参数是整数,但是实际上写到本地文件中的是整数在字符集上对应的字符
3.释放资源
细节:每次使用完流之后都要释放资源
字符流底层原理(缓冲区)
1.创建字符输入/出流对象
底层:关联文件,并创建缓冲区(长度为8192的字节数组)
2.读取数据
1.判断缓冲区中是否有数据可以读取
2.缓冲区没有数据:就从文件中获取数据,装到缓冲区中,每次尽可能装满缓冲区
如果文件中也没有数据了,返回-1
3.缓冲区有数据:从缓冲区中读取。
空参的read方法:一次读取一个字节,遇到中文一次读多个字节,把字节解码并转成十进制返回有参的read方法:把读取字节,解码,强转三步合并了,强转之后的字符放到数组中
注意:
FileWriter默认是不打开续写开关的,因此在读取数据后直接使用FileWriter,会清空文件
但是缓冲区中的数据仍然可以被读取,剩下的文件中的数据无法读取到
高级流
字节缓冲流

1 | //1.创建缓冲流的对象 |
字节缓冲流的最大作用就是使字节流也可以使用缓冲区,从而能够提高文件读写的效率
这是因为缓冲区是开辟在内存中的,而读写过程中字节流所创建的“通道”是连接硬盘和内存的
内存中的读写速率远快于硬盘,从而提高了效率
字节输入缓冲流和字节输出缓冲流都有自己的缓冲区,而第三方变量就在这两个缓冲区之间起着传递数据的作用
字符缓冲流
 字符流本身自带缓冲区,因此字符缓冲流更重要的作用是提供了两个特有的方法
字符缓冲输入流:public String readLine();读取一行数据,直到遇到回车换行结束,但是不会把回车换行读取到内存中,如果没有数据可读了,返回Null
字符缓冲输出流:public void newLine();提供跨平台的换行
字符流本身自带缓冲区,因此字符缓冲流更重要的作用是提供了两个特有的方法
字符缓冲输入流:public String readLine();读取一行数据,直到遇到回车换行结束,但是不会把回车换行读取到内存中,如果没有数据可读了,返回Null
字符缓冲输出流:public void newLine();提供跨平台的换行
拷贝文件的四种方式
字节流的基本流:一次读写一个字节
字节流的基本流:一次读写一个字节数组
字节缓冲流:一次读写一个字节
字节缓冲流:一次读写一个字节数组
其中第二种和第四种方式性能较好
转换流
InputStreamReader和OutputStreamWriter
是字符流和字节流之间的桥梁

作用:
1.按照指定字符编码读取
JDK11前:
1 | InputStreamReader isr = new InputStreamReader(new FileInputStream("myio\\gbkfile.txt"),"GBK"); |
JDK11后:
1 | FileReader fr = new FileReader("myio\\gbkfilg,txt" , charset.forName("GBK")); |
2.字节流想要使用字符流中的方法(缓冲流中的readLine和newLine)
字节流在读取中文的时候,是会出现乱码的,但是字符流可以搞定;
字节流里面是没有读一整行的方法的。只有字符缓冲流才能搞定
序列化流和反序列化流
序列化流ObjectOutputStream可以将一个对象写到本地文件中
构造方法:public ObjectOutputStream (OutputStream out)
成员方法:public final void writeObject(Object obj)将对象序列化写出到文件中,防止被修改
反序列化流ObjectInputStream可以将序列化到本地文件中的对象读取到程序中
构造方法:public ObjectInputStream (InputStream out)
成员方法:public Object readObject()把序列化到本地文件中的对象读取到程序中
注意:
1.要使用序列化流,对象的javabean类必须实现Serilizable接口,这是一个标记式接口,其中不含抽象方法,否则会出现NotSerialzableException异常
2.使用序列化流时,java会通过成员变量等信息计算得到一个版本号,将它和对象信息一起写入文件中,如果后续jacabean类发生修改使得版本号发生改变,导致读取时版本号与javabean中版本号不一致,会发生报错,因此需要固定版本号
private static final long serialVersionUID=1L;
3.如果有不想序列化到文件中的成员变量,可以使用transient关键字,称为瞬态关键字:
private transient String address ;
4.序列化流写到文件中的数据是不能修改的,一但修改就无法再次读回来了
5.将多个自定义对象序列化到文件中,但是对象的个数不确定时,可以将对象添加到ArrayList中,用反序列化流读取ArrayList中的数据再强转为ArrayList,最后再循环获取,这样做的原因是ArrayList也实现了Serilizable接口(可以从ArrayList的源码中获取serialVersionUID)
打印流
PrintStream和Printwriter
特点1:打印流只操作文件目的地,不操作数据源
特点2:特有的写出方法可以实现,数据原样写出
特点3:特有的写出方法可以实现自动刷新,自动换行
打印一次数据=写出+换行+刷新
字节打印流
字节打印流没有缓冲器,开不开自动刷新都一样
构造方法:

成员方法:

字符打印流
字符流有缓冲区,想要自动刷新需要开启
构造方法:

成员方法:

输出语句System.out.println() 再理解
System.out其实就是获取了一个打印流对象,此打印流在虚拟机启动的时候,由虚拟机创建,默认指向控制台,它是一个特殊的打印流,是系统中的标准输出流,不能关闭,否则后面的输出语句都没用了,在系统中是唯一的
解压缩流和压缩流
ZipInputStream和ZipOutputStream
压缩包中的每一个文件(包括文件夹中的文件)可视作一个ZipEntry,解压的本质就是将每一个ZipEntry按照层级拷贝到本地另一个文件夹中
1 | //定义一个方法用来解压 |
1 | //作用:压缩 |
常用工具包
Commons-io
IO流-43-常用工具包(Commons-io)_哔哩哔哩_bilibili





